NLP#
Spell checking
Speech recognition
Translators
Analyse sentiment (positive/negative) of text
Extract topics from text (e.g. news articles)
Generate text (e.g. chatbots)
Search engines (e.g. Google)
…
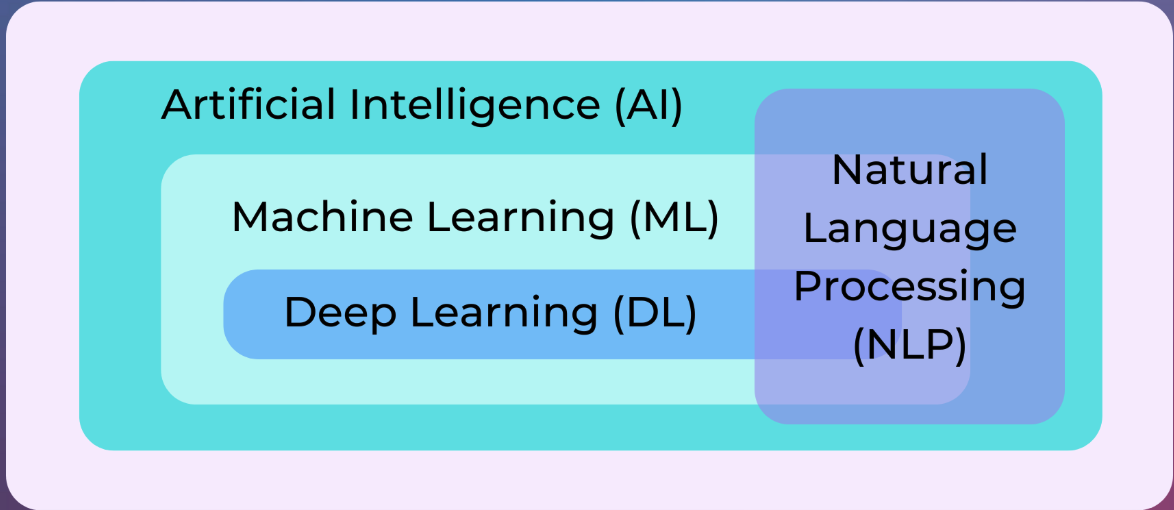
Working with text data#
Algorithms work well with numbers
working with text = meaningfully transforming your data into numbers
meaningful = depends on your application
Converting text into numbers#
this is also called text preprocessing
Text processing → text to numbers#
Local representations
Encoding with a unique number
Statistical Encodings
Distributed Representations
Word Embeddings
Text processing → text to numbers#
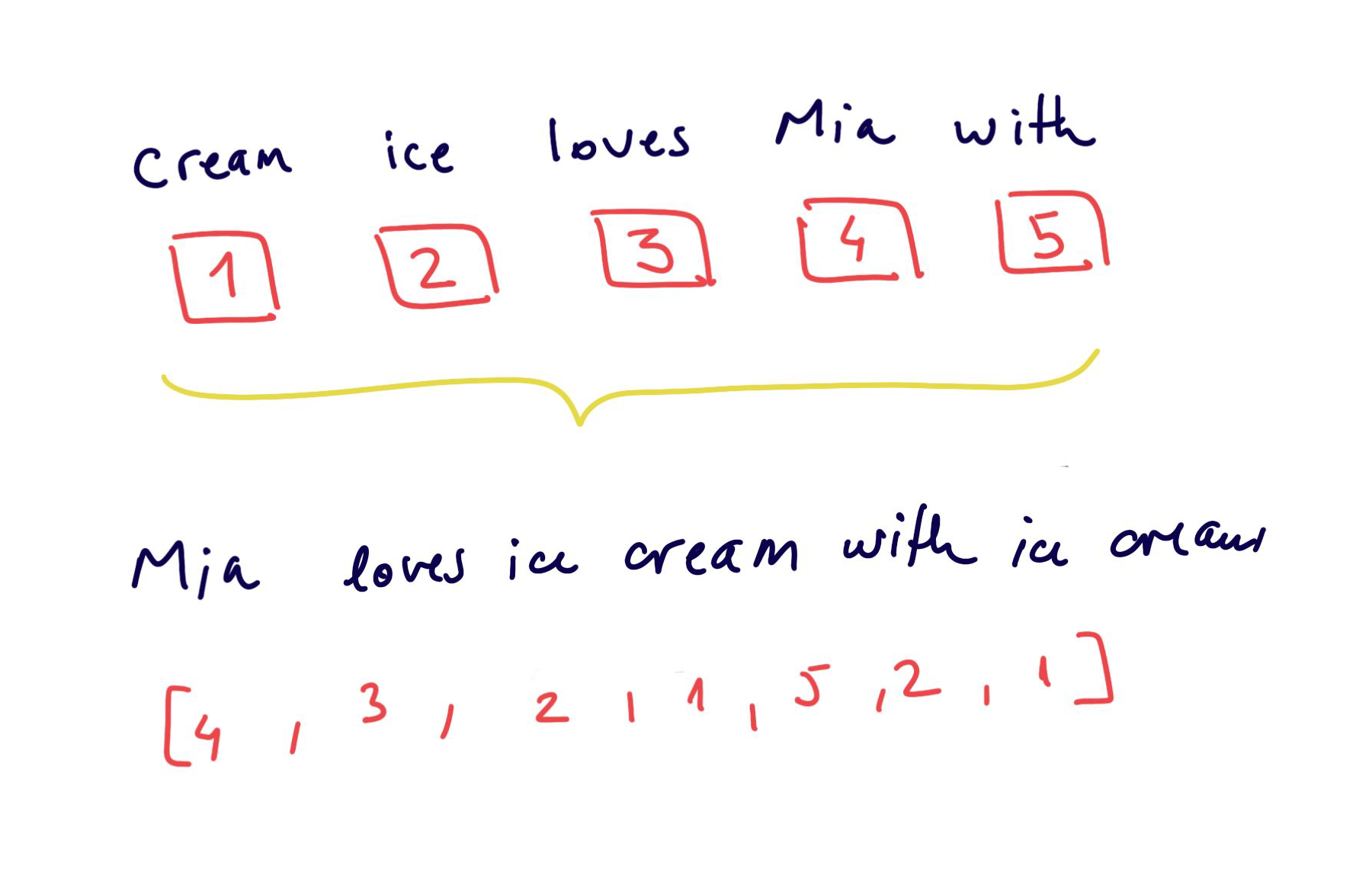
Encoding with a unique number
Easy to create, but the numbers have no relational representation
the relationship between words is not captured
models cannot interpret well these representation
Text processing → text to numbers#
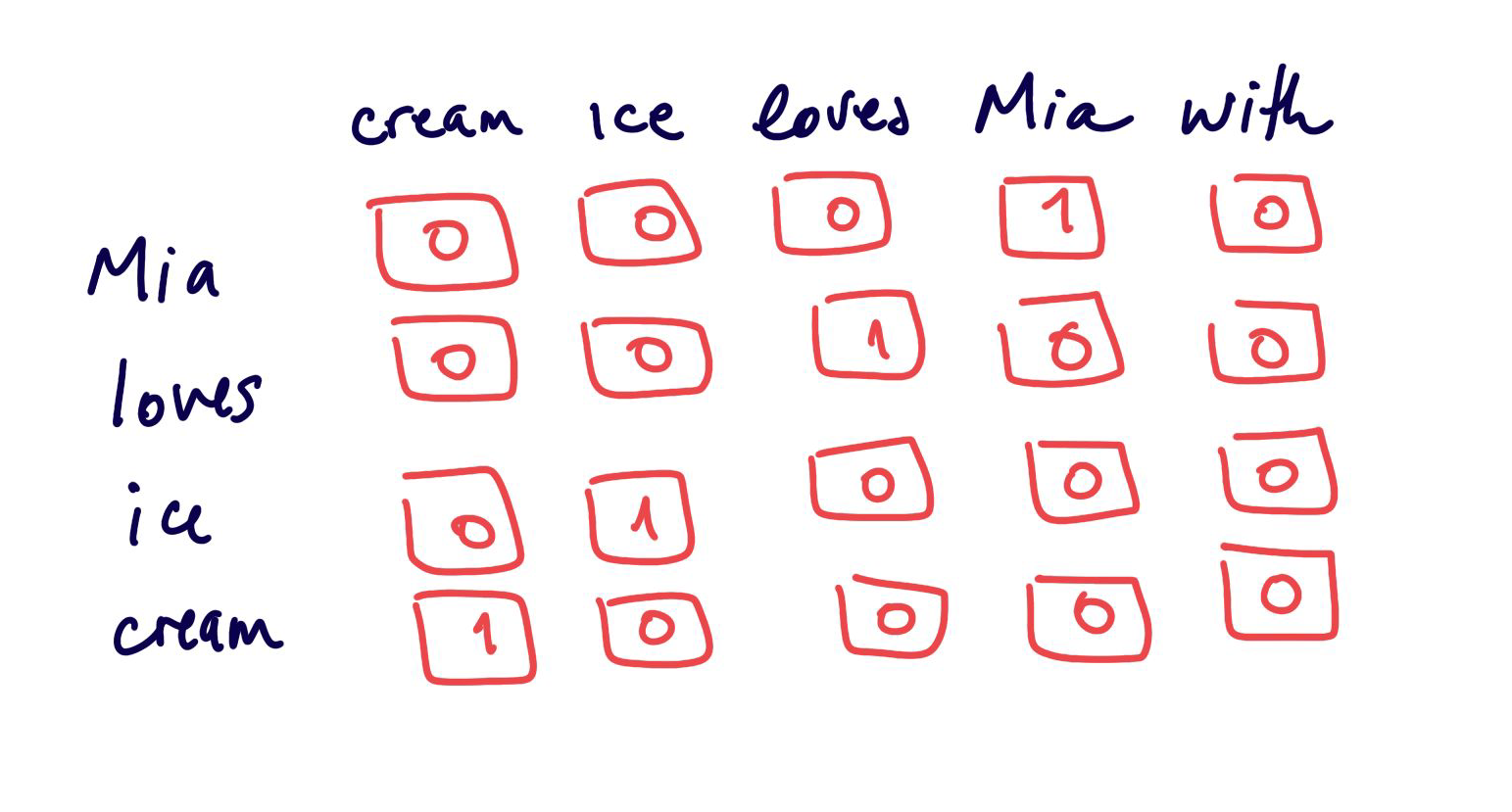
Statistical Encodings
Creating vectors of the size of the vocabulary
leads to large sparse features space
not very efficient
Text processing → text to numbers#
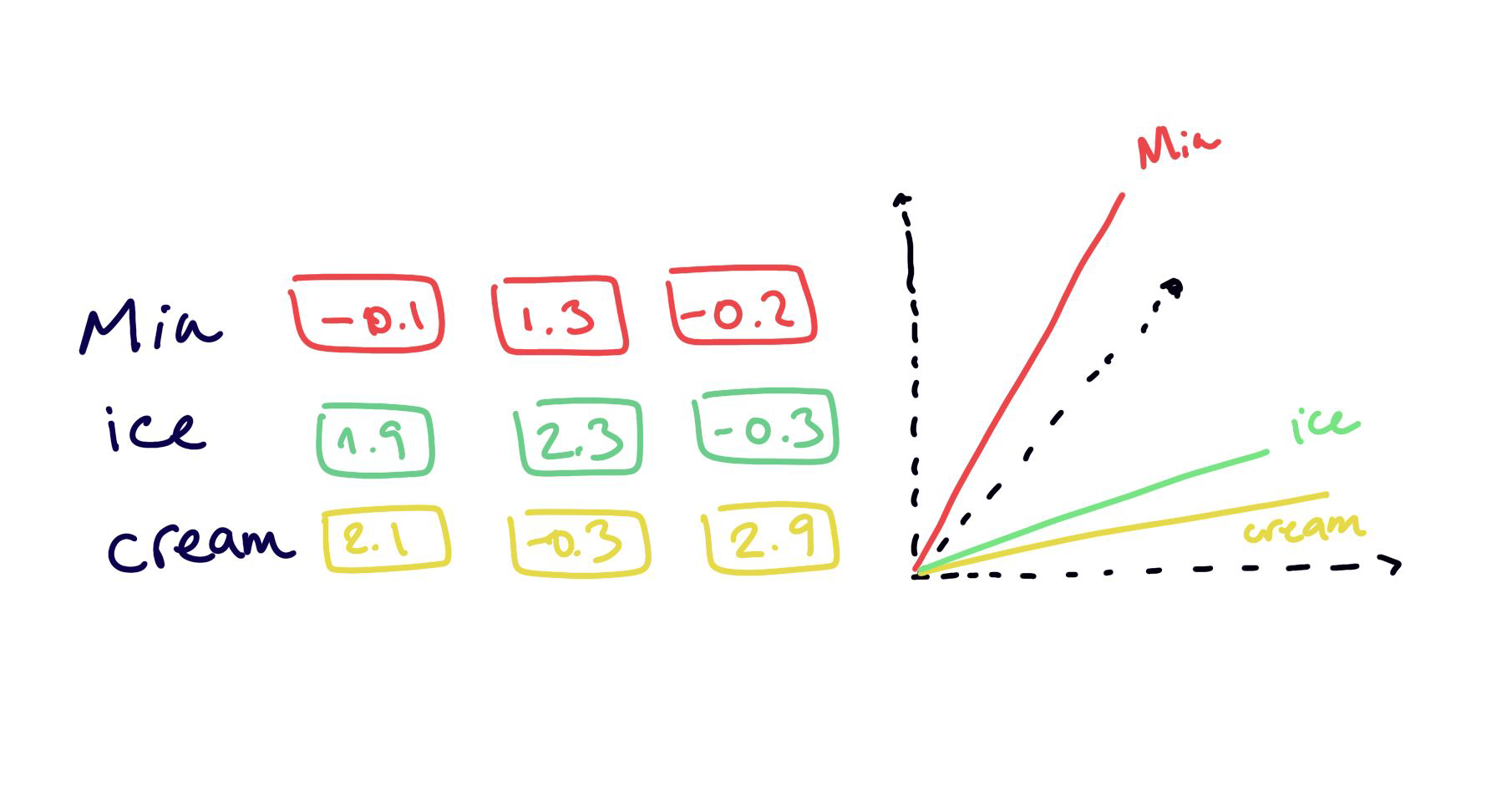
Word Embeddings
embedding = new latent space
properties and relationships between items are preserved
less number of dimensions
less sparseness
Statistical Encodings#
Text Preprocessing#
Tokenization
CountVectorizer
TF-IDF
N-grams
Normalization
Stemming
Lemmatization
Tokenization#

import nltk
nltk.download("punkt")
nltk.download("wordnet")
nltk.download("punkt_tab")
from nltk.tokenize import sent_tokenize, word_tokenize
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
import pandas as pd
text = "Let us learn some NLP. NLP is amazing!"
word_tokenize(text)
['Let', 'us', 'learn', 'some', 'NLP', '.', 'NLP', 'is', 'amazing', '!']
sent_tokenize(text)
['Let us learn some NLP.', 'NLP is amazing!']
CountVectorizer#
Converting a collection of text documents to a matrix of token counts
CountVectorizer#


Gives a lot of weight to frequent (and maybe not so informative) words… → TF-IDF fixes this
corpus = [
'This is the first Document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?'
]
cv = CountVectorizer()
X = cv.fit_transform(corpus)
features = cv.get_feature_names_out()
print(f"Features - {features}")
output = pd.DataFrame(X.toarray(), columns=cv.get_feature_names_out())
print("\n",output)
Features - ['and' 'document' 'first' 'is' 'one' 'second' 'the' 'third' 'this']
and document first is one second the third this
0 0 1 1 1 0 0 1 0 1
1 0 2 0 1 0 1 1 0 1
2 1 0 0 1 1 0 1 1 1
3 0 1 1 1 0 0 1 0 1
from sklearn.linear_model import LogisticRegression
y = ['document 1', 'document 2', 'document 3', 'document 4']
model = LogisticRegression().fit(X, y)
query = ['What is about second document?']
query_transformed = cv.transform(query)
print('prediction:',model.predict(query_transformed)[0])
print('probability:',model.predict_proba(query_transformed)[0])
prediction: document 2
probability: [0.2178996 0.39701782 0.16718298 0.2178996 ]
TF-IDF#
TF-IDF: Term Frequency * Inverse Document Frequency
→ measure how important a word is to a document in a corpus
A frequent word in a document that is also frequent in the corpus is less important to a document than a frequent word in a document that is not frequent in the corpus.
TF-IDF#
TF:
IDF:
TF-IDF:
TF-IDF#

In detail article how Tf-IDF works.
corpus = [
'This is the first Document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
tfidf = TfidfVectorizer()
X = tfidf.fit_transform(corpus)
X.toarray()
array([[0. , 0.46979139, 0.58028582, 0.38408524, 0. ,
0. , 0.38408524, 0. , 0.38408524],
[0. , 0.6876236 , 0. , 0.28108867, 0. ,
0.53864762, 0.28108867, 0. , 0.28108867],
[0.51184851, 0. , 0. , 0.26710379, 0.51184851,
0. , 0.26710379, 0.51184851, 0.26710379],
[0. , 0.46979139, 0.58028582, 0.38408524, 0. ,
0. , 0.38408524, 0. , 0.38408524]])
df = pd.DataFrame((X.toarray().round(2)), columns=tfidf.get_feature_names_out())
df
| and | document | first | is | one | second | the | third | this | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00 | 0.47 | 0.58 | 0.38 | 0.00 | 0.00 | 0.38 | 0.00 | 0.38 |
| 1 | 0.00 | 0.69 | 0.00 | 0.28 | 0.00 | 0.54 | 0.28 | 0.00 | 0.28 |
| 2 | 0.51 | 0.00 | 0.00 | 0.27 | 0.51 | 0.00 | 0.27 | 0.51 | 0.27 |
| 3 | 0.00 | 0.47 | 0.58 | 0.38 | 0.00 | 0.00 | 0.38 | 0.00 | 0.38 |
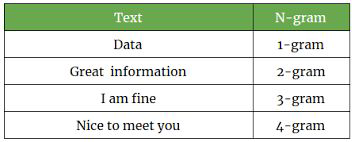
N-grams#
To model sequences of words… for example ice and cream make more sense as a 2-gram when they appear together
can be at word level or at character level
from nltk import ngrams
n = 4
for i in range(1, n):
print(f"{i} gram\n")
ngram = ngrams(text.split(), i)
for gram in ngram:
print(gram)
print("-"*10)
1 gram
('Let',)
('us',)
('learn',)
('some',)
('NLP.',)
('NLP',)
('is',)
('amazing!',)
----------
2 gram
('Let', 'us')
('us', 'learn')
('learn', 'some')
('some', 'NLP.')
('NLP.', 'NLP')
('NLP', 'is')
('is', 'amazing!')
----------
3 gram
('Let', 'us', 'learn')
('us', 'learn', 'some')
('learn', 'some', 'NLP.')
('some', 'NLP.', 'NLP')
('NLP.', 'NLP', 'is')
('NLP', 'is', 'amazing!')
----------
Normalization#
[‘List’, ‘listed’, ‘lists’, ‘listing’, ‘listings’, ‘.’]
→ [‘list’, ‘listed’, ‘lists’, ‘listing’, ‘listings’, ‘.’]
Do we want to distinguish between “List” and “list”?
Sometimes we do: “White House” vs. “white house”
Notes: Normalization is the process of converting text data into a standardized form to reduce complexity and improve the efficiency of machine learning models. This can include lowercasing, stemming/lemmatization, …
Stemming#
[‘list’, ‘listed’, ‘lists’, ‘listing’, ‘listings’, ‘.’]
→ [‘list’, ‘list’, ‘list’, ‘list’, ‘list’, ‘.’]
Stemming reduces words to a shorter form, a form that might have no meaning.
Lemmatization#
[‘list’, ‘listed’, ‘lists’, ‘listing’, ‘listings’, ‘.’]
→ [‘list’, ‘listed’, ‘list’, ‘listing’, ‘listing’, ‘.’]
Lemmatization uses the language dictionary to get the base word of a word.
stemmer = nltk.PorterStemmer()
text = "We are learning how a stemmer works"
text1 = "People are running so fast."
tokenized_text = word_tokenize(text1)
stem = [stemmer.stem(word) for word in tokenized_text]
stem
['peopl', 'are', 'run', 'so', 'fast', '.']
lemmatizer = nltk.WordNetLemmatizer()
tokenized_text = word_tokenize(text1)
lemm = [lemmatizer.lemmatize(word) for word in tokenized_text]
lemm
['People', 'are', 'running', 'so', 'fast', '.']
Stemming or Lemmatization?#
It depends…
Stemming is faster
Lemmatization preserves more information
Stopwords#
some words do not provide meaningful information … they are not “content words”
the list of non-content words is language specific and corpus specific
What would you say are stop words in this text?
“Apple is looking at buying U.K. startup for $1 billion”
Stopwords#
some words do not provide meaningful information … they are not “content words”
the list of non-content words is language specific and corpus specific
What would you say are stop words in this text?
“Apple is looking at buying U.K. startup for $1 billion”
nltk.download("stopwords")
from nltk.corpus import stopwords
print(stopwords.words('english'))
['a', 'about', 'above', 'after', 'again', 'against', 'ain', 'all', 'am', 'an', 'and', 'any', 'are', 'aren', "aren't", 'as', 'at', 'be', 'because', 'been', 'before', 'being', 'below', 'between', 'both', 'but', 'by', 'can', 'couldn', "couldn't", 'd', 'did', 'didn', "didn't", 'do', 'does', 'doesn', "doesn't", 'doing', 'don', "don't", 'down', 'during', 'each', 'few', 'for', 'from', 'further', 'had', 'hadn', "hadn't", 'has', 'hasn', "hasn't", 'have', 'haven', "haven't", 'having', 'he', "he'd", "he'll", 'her', 'here', 'hers', 'herself', "he's", 'him', 'himself', 'his', 'how', 'i', "i'd", 'if', "i'll", "i'm", 'in', 'into', 'is', 'isn', "isn't", 'it', "it'd", "it'll", "it's", 'its', 'itself', "i've", 'just', 'll', 'm', 'ma', 'me', 'mightn', "mightn't", 'more', 'most', 'mustn', "mustn't", 'my', 'myself', 'needn', "needn't", 'no', 'nor', 'not', 'now', 'o', 'of', 'off', 'on', 'once', 'only', 'or', 'other', 'our', 'ours', 'ourselves', 'out', 'over', 'own', 're', 's', 'same', 'shan', "shan't", 'she', "she'd", "she'll", "she's", 'should', 'shouldn', "shouldn't", "should've", 'so', 'some', 'such', 't', 'than', 'that', "that'll", 'the', 'their', 'theirs', 'them', 'themselves', 'then', 'there', 'these', 'they', "they'd", "they'll", "they're", "they've", 'this', 'those', 'through', 'to', 'too', 'under', 'until', 'up', 've', 'very', 'was', 'wasn', "wasn't", 'we', "we'd", "we'll", "we're", 'were', 'weren', "weren't", "we've", 'what', 'when', 'where', 'which', 'while', 'who', 'whom', 'why', 'will', 'with', 'won', "won't", 'wouldn', "wouldn't", 'y', 'you', "you'd", "you'll", 'your', "you're", 'yours', 'yourself', 'yourselves', "you've"]
[nltk_data] Downloading package stopwords to /home/runner/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
POS Tagging#
Part Of Speech tagging - assigning grammatical annotations
ADJ - adjective
NOUN
VERB
…
Which are verbs and nouns here?
“Apple is looking at buying U.K. startup for $1 billion”
POS Tagging#
Part Of Speech tagging - assigning grammatical annotations
ADJ - adjective
NOUN
VERB
…
Which are verbs and nouns here?
“Apple is looking at buying U.K. startup for $1 billion”
from nltk import pos_tag
nltk.download('averaged_perceptron_tagger_eng')
[nltk_data] Downloading package averaged_perceptron_tagger_eng to
[nltk_data] /home/runner/nltk_data...
[nltk_data] Unzipping taggers/averaged_perceptron_tagger_eng.zip.
True
tokenized_text = word_tokenize(text1)
tag = pos_tag(tokenized_text)
tag
[('People', 'NNS'),
('are', 'VBP'),
('running', 'VBG'),
('so', 'RB'),
('fast', 'RB'),
('.', '.')]
PRP = Personal pronoun
VBP - Verb, non-3rd person singular present
VBG - Verb, ending in ‘-ing’ or present participle
VBZ - Verb, 3rd person singular present
WRB - Wh-adverb
NN - Noun, singular or mass
RB - Adverb
POS Tagging using Spacy#
!pip install spacy
!python -m spacy download en_core_web_sm
import spacy
nlp = spacy.load("en_core_web_sm")
# new_text = "The car is blue"
doc = nlp(text1)
# Token and Tag
for token in doc:
print(token, token.pos_)
People NOUN
are AUX
running VERB
so ADV
fast ADV
. PUNCT
PRON - Pronoun
NOUN - Noun
VERB - Verb
AUX - Auxiliary
DET - Determiner
SCONJ - Conjunction
Named Entities#
Named Entities are real-world objects that are assigned a name: person, country, book, product..
The recognition of entities is based on training data so it’s not perfect.
What entities do you think are in this text?
“Apple is looking at buying U.K. startup for $1 billion”
Named Entities#
Named Entities are real-world objects that are assigned a name: person, country, book, product..
The recognition of entities is based on training data so it’s not perfect.
What entities do you think are in this text?
“Apple is looking at buying U.K. startup for $1 billion”
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for ent in doc.ents:
print(ent.text," - ", ent.label_)
Apple - ORG
U.K. - GPE
$1 billion - MONEY
GPE - Geographical Entity
ORG - Organization
MONEY - Monetary value
from spacy import displacy
displacy.render(doc, style="ent")
for token in doc:
print(token, token.pos_)
Apple PROPN
is AUX
looking VERB
at ADP
buying VERB
U.K. PROPN
startup NOUN
for ADP
$ SYM
1 NUM
billion NUM
displacy.render(doc, style="dep")
So.. what do we do with all that?#
document similarity
text classification
…
Text similarity or Document Similarity#
Each document is a vector of features.
Similarity between documents is the similarity between vectors
Usage:
search engines: query to document
clustering of documents: document to document
Question & Answering platforms: query to query
Text classification#
You can use your favourite classifier with text
Logistic Regression provides nice baseline
AUC score as performance metric
Some applications:
spam detection
sentiment analysis
hate speech analysis
Word Embeddings#
Word Embeddings#
Represent feature space in smaller dimension
Similar words are near in embedding space
Trained by using neural networks
→ Use those trained weights as first layer in your NLP neural network.
Word similarity#
Is “St Pauli” more similar to:
De Wallen → Similar type
or
HSV → Similar topic?
Result depends on the context … or on the feature space / embedding you chose
Using Embeddings#
Relevant items for your task should be similar in the embedding space / i.e close to each other.
.
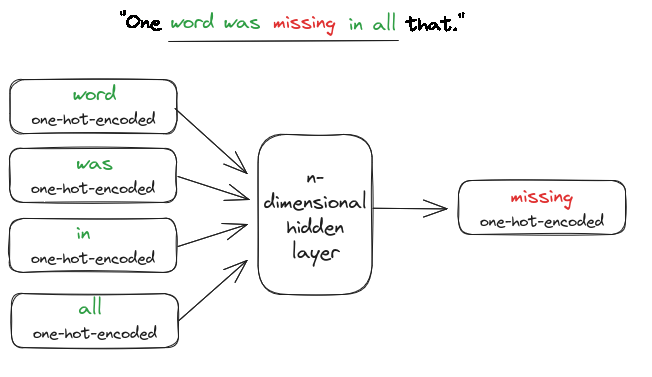
How do we get Word Embeddings#
CBOW - Continuous Bag of Words
Predict the current word based on the context words
Input (X): context words , Output (y): current word
For example, “One word was missing in all that.”
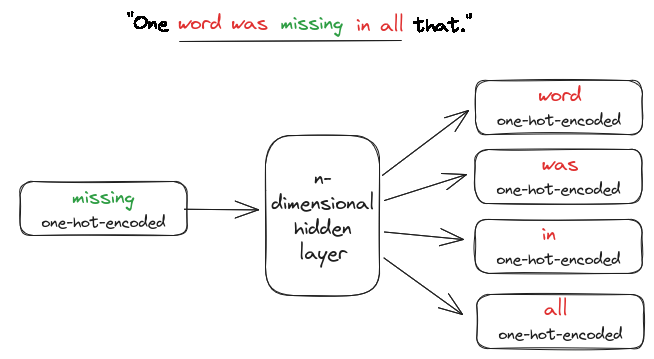
How do we get Word Embeddings#
Skip-Gram
Predict the context words based on the current word
Input (X): current word, Output (y): context words
For example, “One word was missing in all that.”
How do we get Word Embeddings#


Using pre-trained embeddings#
Most times you do not have enough data to get good word embeddings for your task, instead you can use pre-trained word embeddings.
There are different kinds of word embeddings:
static word embeddings: Word2vec (google), GloVe (Standford University), fastText (Facebook),
contextual word embeddings: ELMo, Bert (google), gpt-2/3/4 (openAI), …
example: pretrained word embeddings
Word Embeddings#
!pip install gensim
!pip install scipy==1.12
import gensim.downloader as api
## List available embeddings
info = api.info()
for model_name, model_data in sorted(info['models'].items()):
print(model_name)
__testing_word2vec-matrix-synopsis
conceptnet-numberbatch-17-06-300
fasttext-wiki-news-subwords-300
glove-twitter-100
glove-twitter-200
glove-twitter-25
glove-twitter-50
glove-wiki-gigaword-100
glove-wiki-gigaword-200
glove-wiki-gigaword-300
glove-wiki-gigaword-50
word2vec-google-news-300
word2vec-ruscorpora-300
# caveat: If you don't have enough RAM, this cell can crash your kernel
wv = api.load("word2vec-google-news-300")
glove = api.load("glove-twitter-100")
fasttext = api.load("fasttext-wiki-news-subwords-300")
wv.most_similar("coffee", topn=10)
[('coffees', 0.721267819404602),
('gourmet_coffee', 0.7057086825370789),
('Coffee', 0.6900454759597778),
('o_joe', 0.6891065835952759),
('Starbucks_coffee', 0.6874972581863403),
('coffee_beans', 0.6749704480171204),
('latté', 0.664122462272644),
('cappuccino', 0.662549614906311),
('brewed_coffee', 0.6621608138084412),
('espresso', 0.6616826057434082)]
wv.get_vector("coffee").shape
(300,)
glove.most_similar("coffee", topn=10)
[('tea', 0.8275877237319946),
('beer', 0.7744594216346741),
('breakfast', 0.7694926261901855),
('coffe', 0.762207567691803),
('starbucks', 0.7606451511383057),
('food', 0.75710529088974),
('wine', 0.7540071606636047),
('drink', 0.7533924579620361),
('milk', 0.7433452010154724),
('cream', 0.7419354915618896)]
wv.distance("coffee", "tea")
# wv.distance("coffee","coffees")
0.43647074699401855
wv.distance("coffee", "onion")
0.8041959255933762
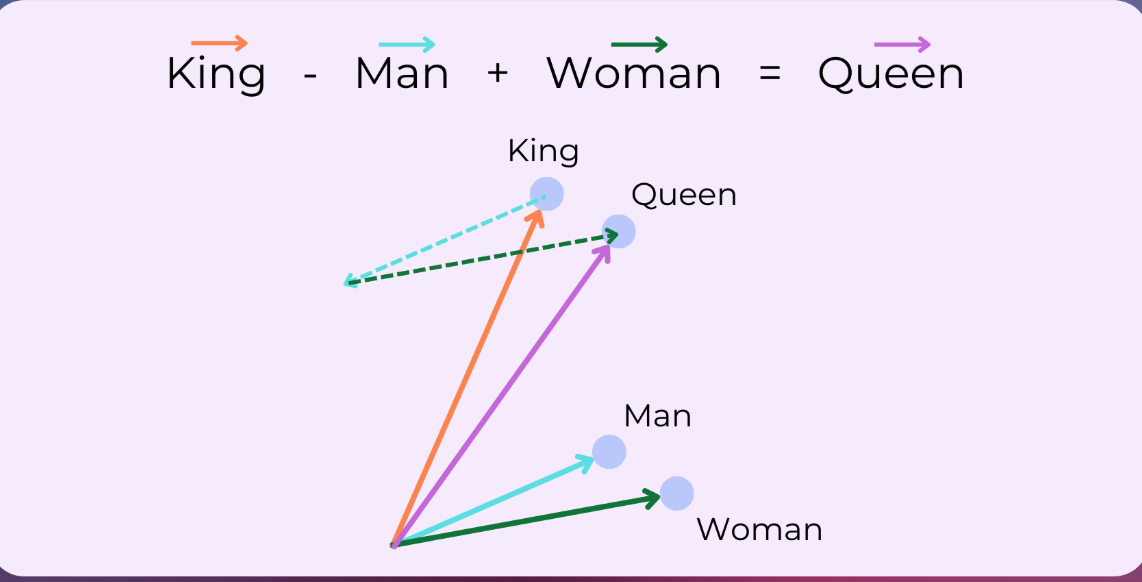
Semantic relationships#
wv.most_similar(positive=["king", "woman"], negative=["man"], topn=5)
[('queen', 0.7118192911148071),
('monarch', 0.6189674735069275),
('princess', 0.5902431011199951),
('crown_prince', 0.5499460697174072),
('prince', 0.5377321243286133)]
Capture Semantic relationships:
gender (man ↔ woman)
royalty (king ↔ queen)
Visualize Semantics with Graphs#
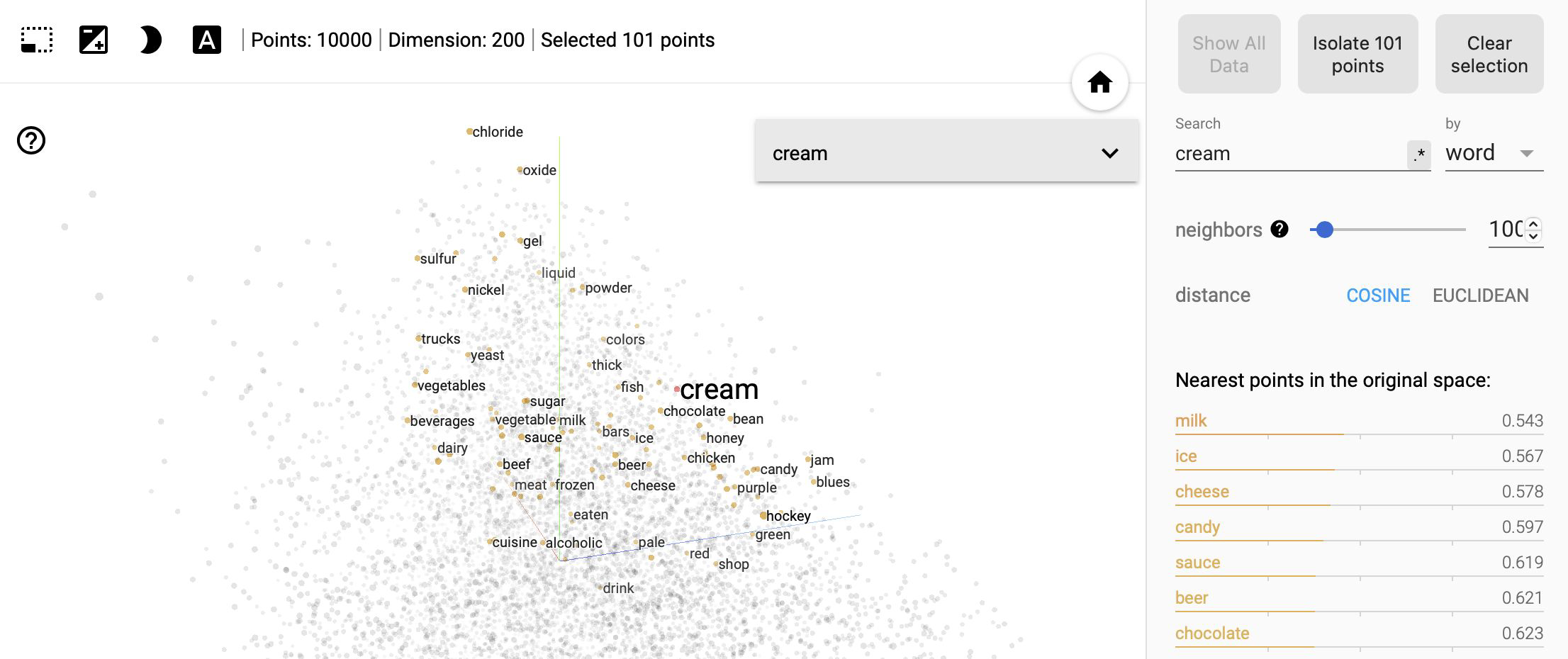
Hugging Face & Transformers#

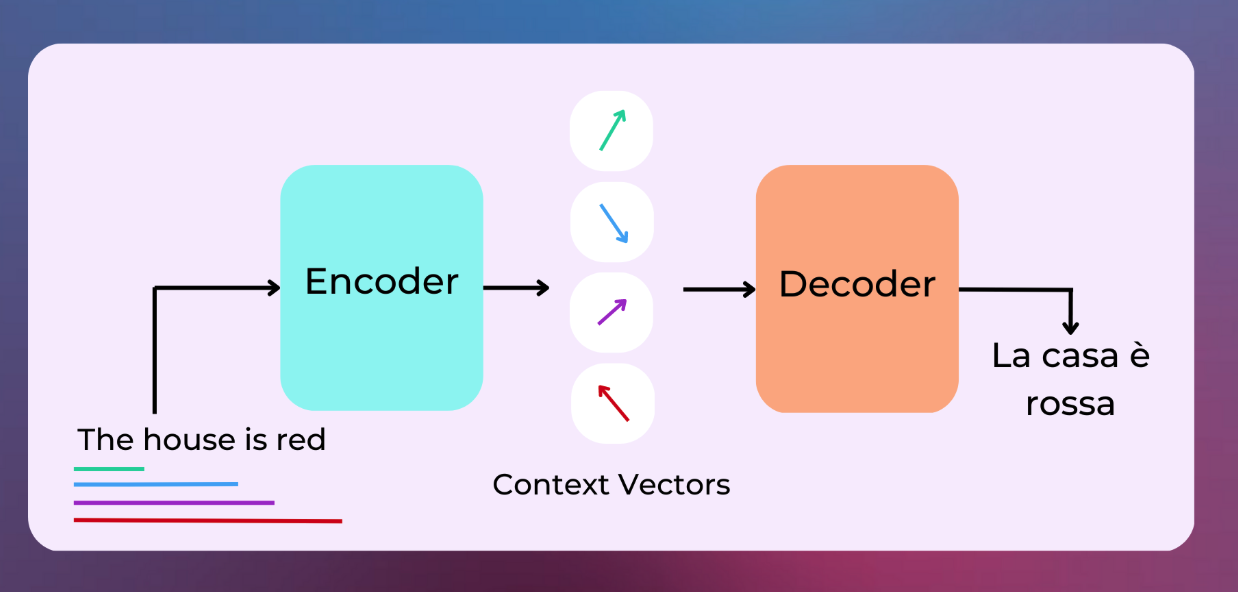
Transformers#
Neural network architecture
Sequences of Encoders and Decoders
Use self-attention mechanisms to process input data in parallel
Handle long-range dependencies in text using many context vectors.
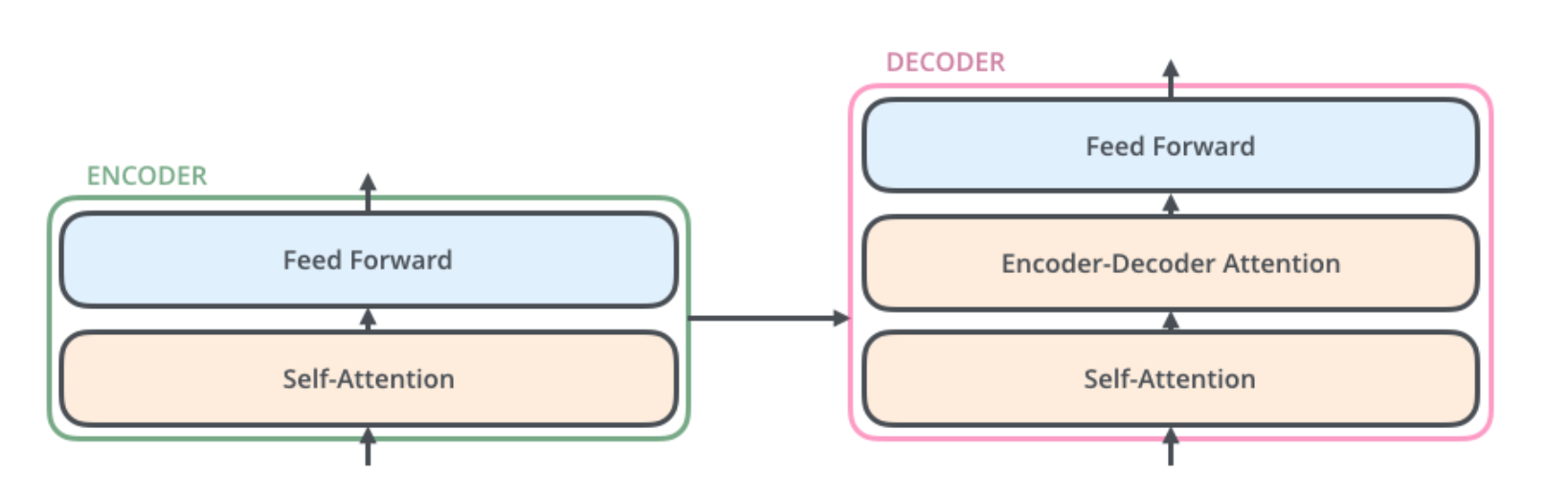
Transformers#
Encoder:
Self-attention layer:
looks at other words in the input sentence as it encodes a specific word
Feed-forward neural network:
applied to each position of the input sentence.
Decoder:
Encoder-Decoder-Attention layer:
helps the decoder focus on relevant parts of the input sentence
Transformers#
Is the term it connected to animal or street ?
self-attention allows the model to associate it with animal.
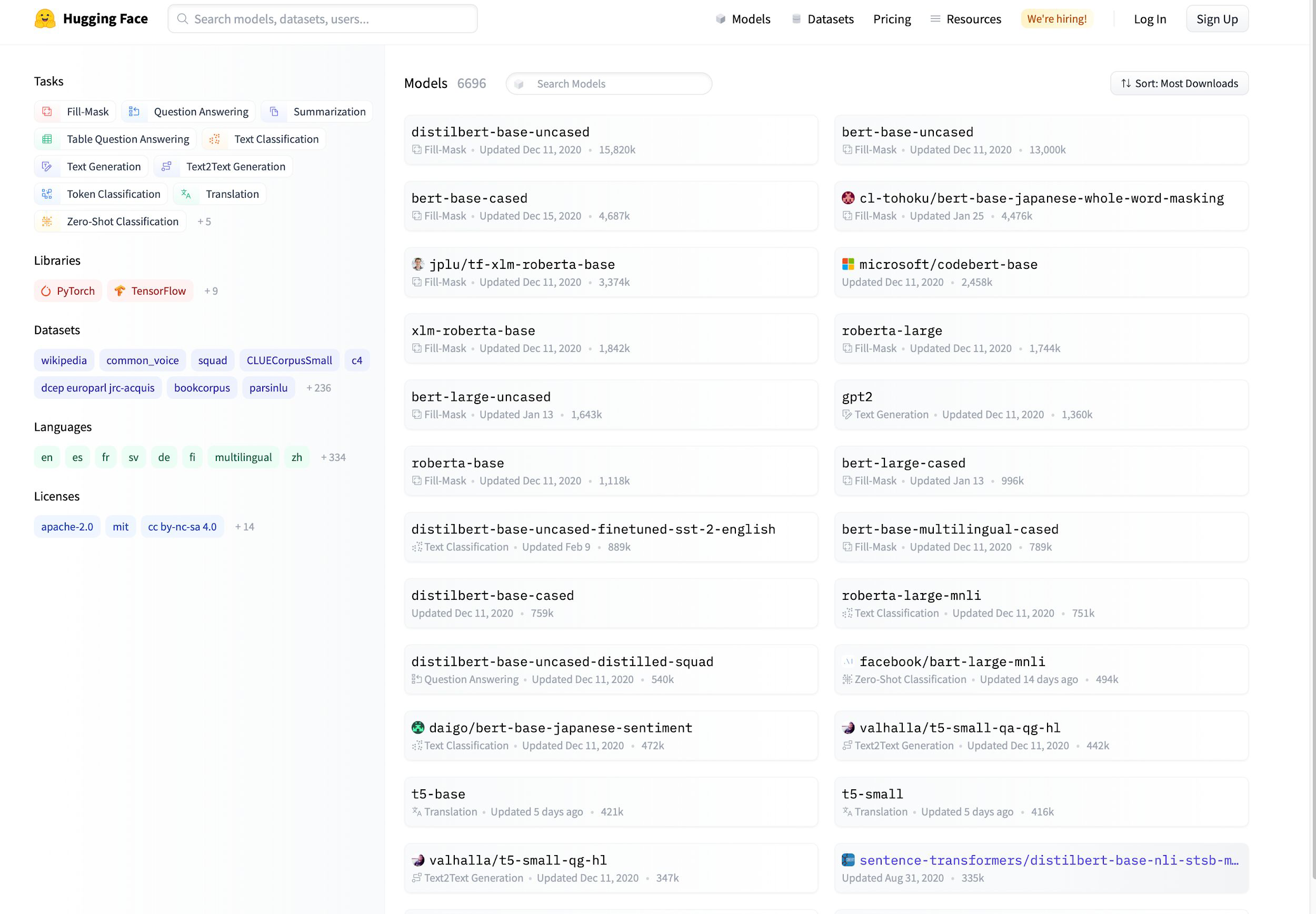
Hugging Face#
> 7k pre trained NLP models on huggingface.co
Zero-Shot Learning#
A pretrained model performs a downstream task directly from a natural language description
input: “Classify the sentiment of: Today is a great day!!”
(see notebook 2,3 in workbooks)
Resources#
Sentiment Analysis with VADER [stand alone, using nltk]